Warum ich 2026 noch immer mit R programmiere
Über Muttersprachen, Qualitätsgräben und das stille Comeback einer unterschätzten Sprache.
R
Python
DataScience
Programmierung
R oder Python? Diese Frage ist in der Data-Science-Community so oft gestellt worden, dass sie sich fast schon als Meme qualifiziert hat — Artikel, Blogposts, LinkedIn-Threads, Konferenzpanels. Die Debatte läuft seit Jahren auf Dauerschleife. Warum also noch einmal? Weil ich als jemand, der seit über zwei Jahrzehnten mit R arbeitet, den Eindruck habe, dass viele Beiträge zu dieser Debatte entweder aus der Python-Perspektive kommen oder R auf seine Schwächen reduzieren. Dieser Post ist kein neutraler Vergleich — er ist eine ehrliche Bestandsaufnahme aus der Perspektive eines R-Nutzers, der Python kennt, schätzt und trotzdem immer wieder zu R zurückkehrt.
Als ich 2003 mit dem Statistikstudium begann 🙈, begegnete ich zum ersten Mal einer Programmiersprache, die eigens für den Umgang mit Daten entworfen worden war: S, beziehungsweise dessen kommerziellen Ableger S-Plus. Beide waren in akademischen Statistikabteilungen damals weit verbreitet — schwerfällig, proprietär, teuer, aber methodisch präzise. Der Übergang zu R, das John Chambers und später ein wachsendes globales Netzwerk von Wissenschaftlerinnen und Wissenschaftlern als freie, quelloffene Alternative aufbauten, vollzog sich dann fast organisch. Es war einfach besser — und kostenlos.
Seitdem ist R in meinem Werkzeugkasten geblieben. Wer eine Sprache im Studium lernt, lernt sie auf eine andere Art als alles, was danach kommt: tiefer, manchmal bruchstückhafter, aber irgendwie prägender. R ist, wenn man so möchte, meine programmatische Muttersprache. Und was man als Muttersprache gelernt hat, gibt man nicht einfach auf — jedenfalls nicht ohne guten Grund.
Dass ich sie behalten habe, liegt aber nicht an Nostalgie. Dafür gibt es Argumente.
Eine Minderheitensprache — mit Comeback
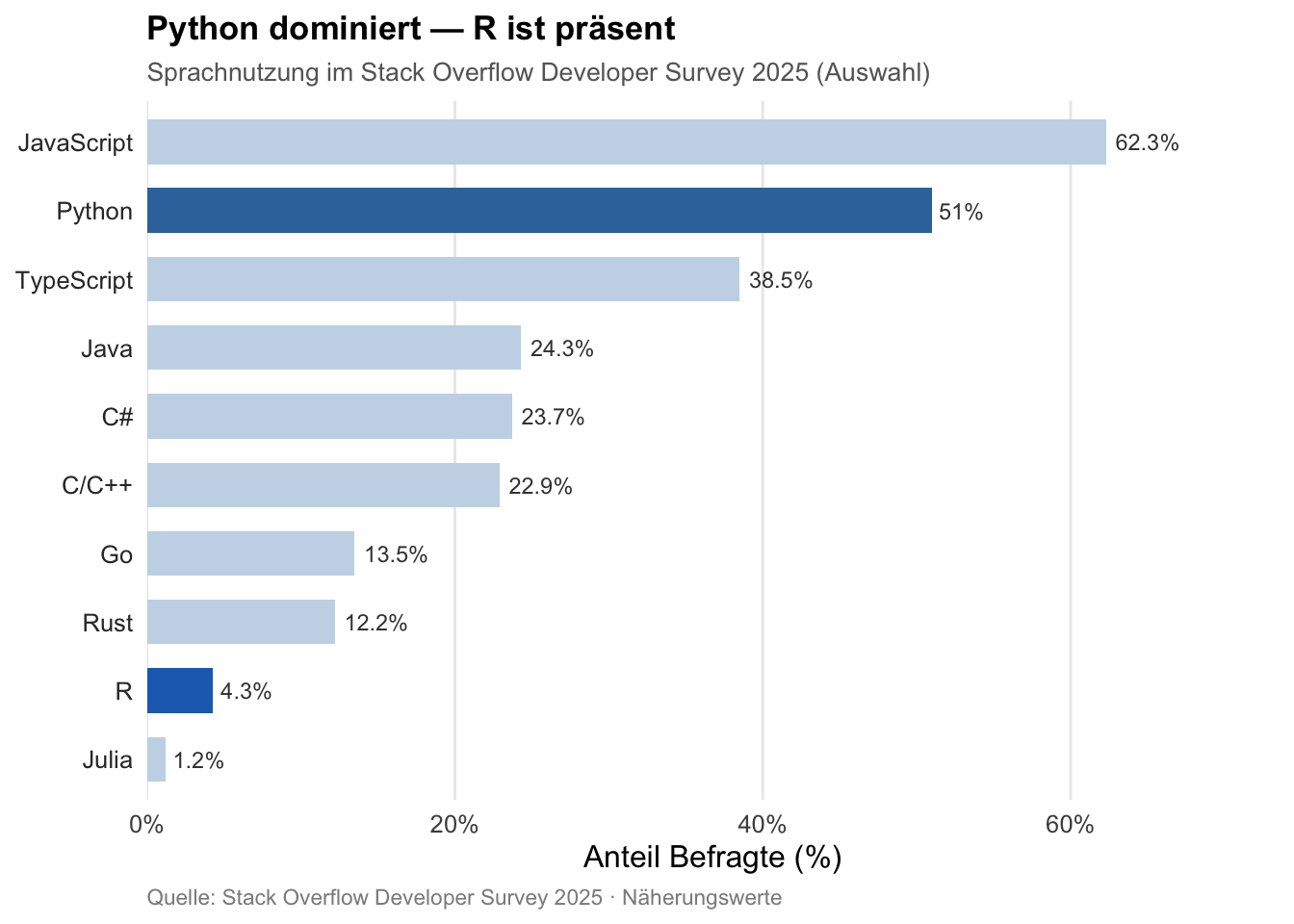
Nüchtern betrachtet sieht die Welt im Jahr 2026 zunächst ernüchternd aus für R-Nutzende. Python dominiert. Laut dem Stack Overflow Developer Survey 2025 ist Python die meistgewünschte Sprache unter Entwicklerinnen und Entwicklern weltweit, mit einem Zuwachs von sieben Prozentpunkten gegenüber dem Vorjahr — der größte Einzeljahressprung seit über einem Jahrzehnt (vgl. Abbildung 2).1 Wer heute eine Stelle als Data Scientist sucht, findet Python in der überwältigenden Mehrheit der Stellenanzeigen; R kommt vor, aber deutlich seltener.2 Gemessen an reinen Nutzungszahlen ist R eine Minderheitensprache — und das wissen auch jene, die sie täglich verwenden.
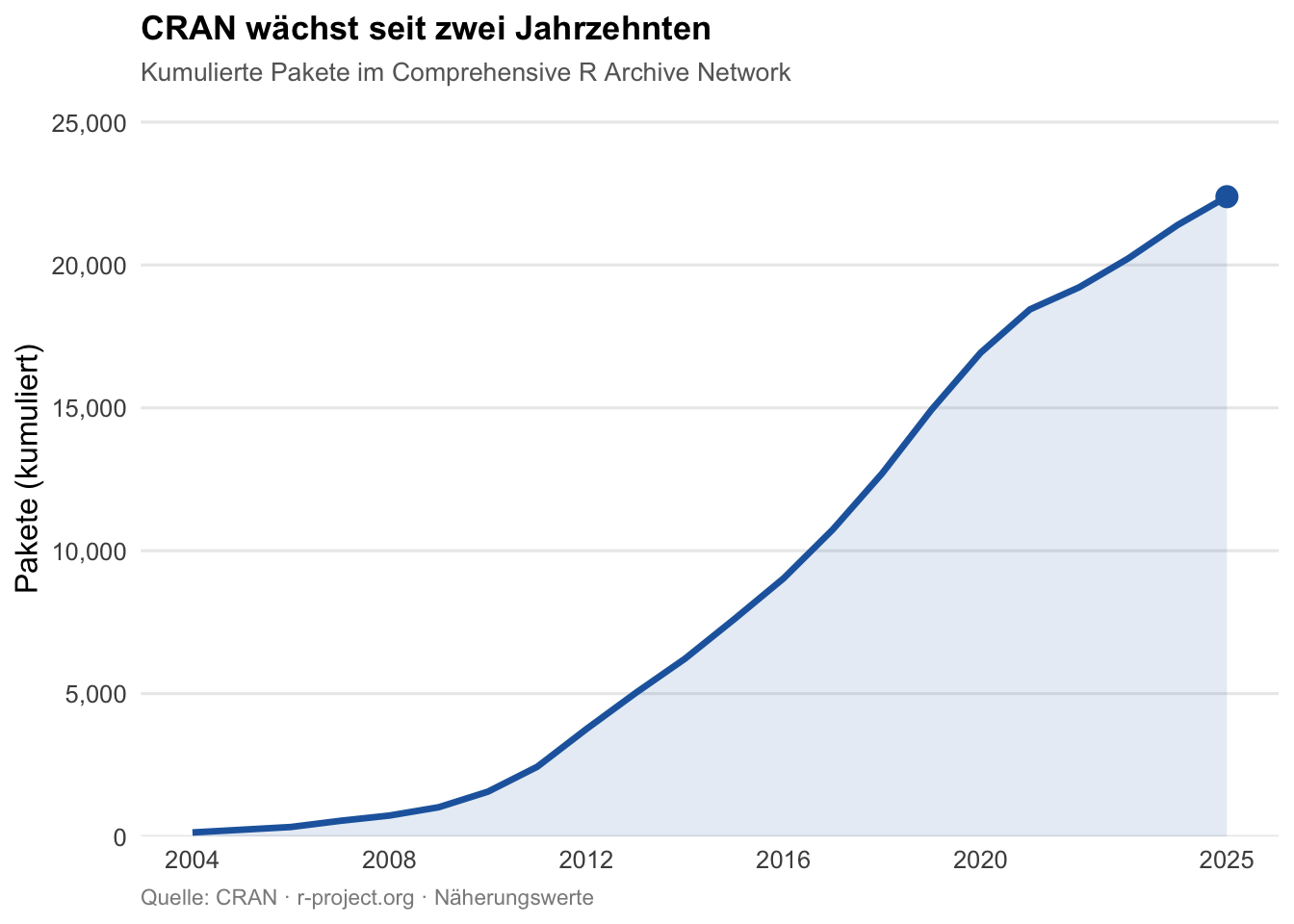
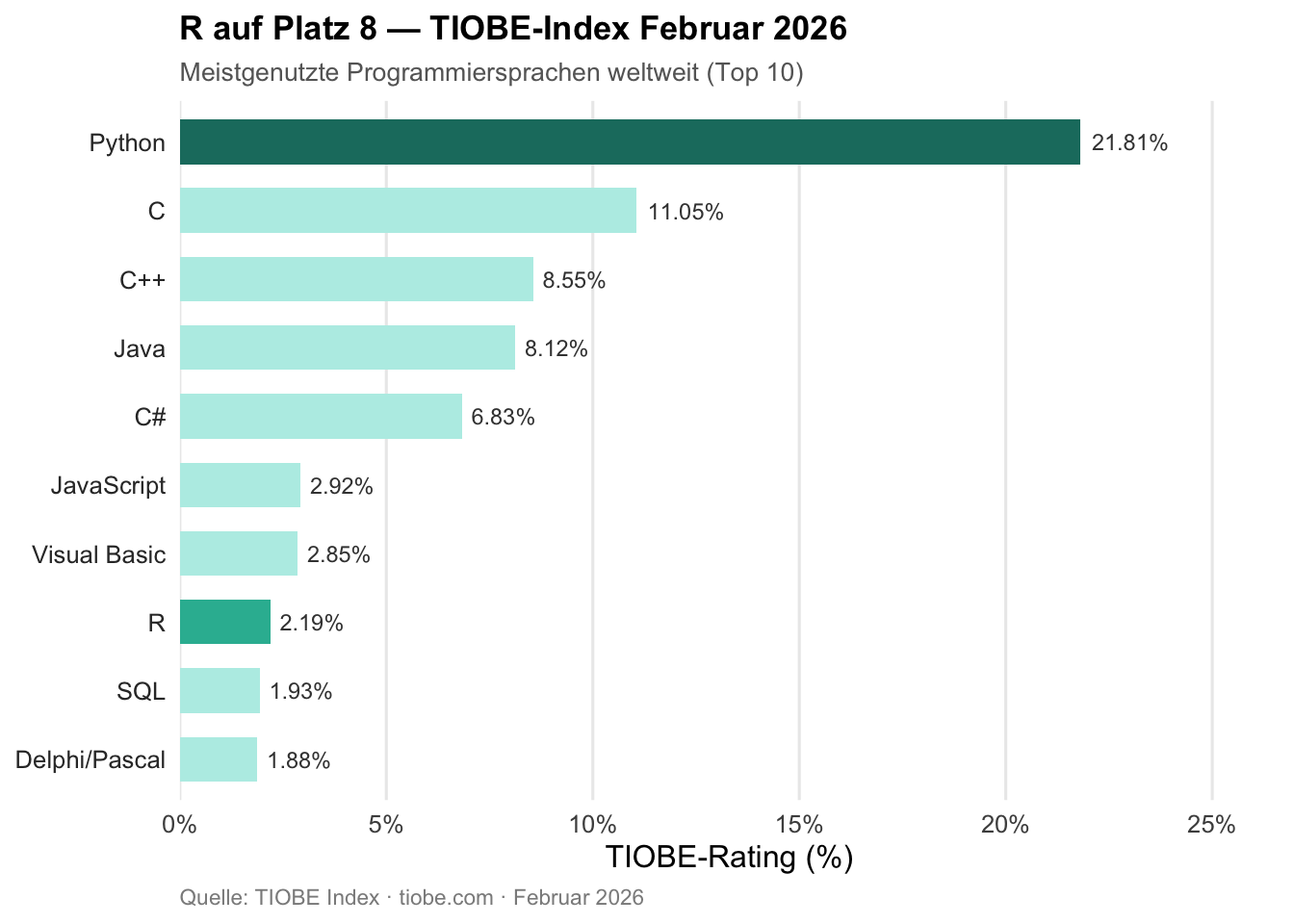
Und doch: Im TIOBE-Index vom Februar 2026 belegt R Platz 8 der meistgenutzten Programmiersprachen weltweit — nach Rang 15 noch im Februar 2025 ein Sprung um sieben Plätze (vgl. Abbildung 3).3 Das ist kein Ausreißer, sondern Ausdruck einer anhaltenden Relevanz in genau jenen Domänen, für die R entworfen wurde: Statistik, Forschung, reproduzierbare Datenanalyse. Auch mit Stand Juni 2025 zählt CRAN — das Comprehensive R Archive Network — bereits 22.390 beigetragene Pakete (vgl. Abbildung 1).4 Eine Sprache, die stirbt, sieht anders aus.
CRAN und die Philosophie der geteilten Verantwortung
Der vielleicht unterschätzteste Vorteil von R liegt nicht in der Sprache selbst, sondern in der Art, wie ihr Paketökosystem organisiert ist. Entscheidend ist nicht, wie viele Pakete es gibt, sondern wie sie auf CRAN gelangen und dort verbleiben.
Jedes Paket durchläuft einen mehrstufigen Prüfprozess: R CMD CHECK validiert Funktionalität, Dokumentation und Codequalität. Was dabei wirklich bemerkenswert ist: CRAN prüft nicht nur das eingereichte Paket selbst, sondern führt automatisch die Testsuite aller Pakete durch, die davon abhängen — auch dann, wenn diese anderen Autorinnen und Autoren gehören. Ein Paketupdate, das irgendwo im Abhängigkeitsnetz Risse verursacht, wird nicht veröffentlicht, bis diese Risse behoben sind. Die Softwareingenieurin Julie Tibshirani beschreibt ihre erste Begegnung mit diesem Mechanismus treffend: „CRAN had also rerun the tests for all packages that depend on mine, even if they don’t belong to me!“5
Diese Idee lässt sich konzeptuell gut greifen: CRAN behandelt das gesamte Ökosystem wie ein gemeinsames Monorepo — so als würden alle Pakete in einem einzigen, gemeinsam gepflegten Repository leben. Die Last liegt bei den Entwicklerinnen und Entwicklern, nicht bei den Nutzerinnen und Nutzern. Das erzeugt Reibung auf der einen Seite, aber Verlässlichkeit auf der anderen. In der Praxis bedeutet das: Wer in R arbeitet, kann darauf vertrauen, dass install.packages("tidyverse") heute genauso funktioniert wie in sechs Monaten — ohne manuelle Eingriffe, ohne Versionspinning, ohne Konfliktauflösung.
Ergänzend dazu gibt es renv, ein Paket zur projektspezifischen Verwaltung von Abhängigkeiten in R.6 Jedes Projekt hält seine eigene Bibliothek mit exakt den Paketversionen, die zum Zeitpunkt der Analyse verwendet wurden — reproduzierbar, portabel, isoliert. Für wissenschaftliche Arbeiten, bei denen Ergebnisse auch in zwei oder fünf Jahren noch exakt reproduzierbar sein müssen, ist das kein Komfort, sondern eine Grundvoraussetzung.
Ein Ökosystem, das Maßstäbe setzt
Was mich an R über die Sprache selbst hinaus hält, ist das Ökosystem, das aus ihr gewachsen ist — und das in mehrfacher Hinsicht Maßstäbe gesetzt hat, die anderswo bis heute nicht vollständig erreicht wurden.
Den Anfang macht das tidyverse: eine kohärente Sammlung von Paketen für den gesamten Datenanalyseworkflow — von der Datenbereinigung (tidyr, dplyr) über das Einlesen (readr) bis zur Visualisierung —, die auf einer gemeinsamen Designphilosophie und einer einheitlichen Grammatik basiert.7 Entwickelt maßgeblich von Hadley Wickham und seinem Team, hat das tidyverse die Art, wie Datenanalyse in R geschrieben und gelesen wird, grundlegend verändert. Was vorher heterogen und inkonsistent war, wurde zu einer Sprache innerhalb der Sprache.
Das tidymodels-Framework erweitert diese Philosophie konsequent auf das maschinelle Lernen.8 Mit parsnip lassen sich über 100 Modellimplementierungen — von linearer Regression über Random Forests bis zu Gradient Boosting — hinter einer einzigen, konsistenten Schnittstelle aufrufen: Wer einmal gelernt hat, wie man ein Modell spezifiziert, kann jedes andere ohne Umlernen einsetzen. recipes übernimmt das Feature Engineering in reproduzierbaren, wiederverwendbaren Schritten; rsample standardisiert Kreuzvalidierung und Resampling; tune automatisiert die Hyperparameter-Optimierung. Das Ergebnis ist ein ML-Workflow, der genau so kohärent ist wie die Datenanalyse im tidyverse — und der sich mit workflows zu vollständigen, reproduzierbaren Pipelines zusammensetzen lässt.
Als komplementärer Ansatz verdient mlr3 besondere Erwähnung — ein modernes, objektorientiertes Framework für maschinelles Lernen in R.9 Während tidymodels auf der tidy-Philosophie aufbaut, setzt mlr3 auf ein konsequent objektorientiertes Design mit R6-Klassen, das besonders für komplexe ML-Experimente und systematische Benchmarking-Studien geeignet ist. Die mlr3verse-Erweiterungen decken ein breites Spektrum ab: von mlr3pipelines für Preprocessing-Pipelines über mlr3tuning für Hyperparameter-Optimierung bis zu mlr3benchmark für systematische Modellvergleiche. Gerade in der Forschung, wo eine große Anzahl von Modellen, Lernaufgaben und Resampling-Strategien systematisch verglichen werden soll, bietet mlr3 eine Ausdrucksstärke und Flexibilität, die in dieser Form in Python kaum zu finden ist (vgl. Abbildung 4).

Das prominenteste Einzelbeispiel aus diesem Ökosystem ist ggplot2.10 Es basiert auf der Grammar of Graphics — einer kohärenten Designphilosophie, die Visualisierung als Komposition von Schichten begreift: Daten, Ästhetiken, Geometrien, Koordinatensysteme. Das Ergebnis ist eine Ausdrucksstärke, die in der Python-Welt bis heute ihresgleichen sucht. Mit plotnine existiert ein direkter Python-Port von ggplot2, der konzeptuell überzeugt — aber in Bezug auf Reife, Dokumentation und Community-Tiefe noch nicht das Niveau des Originals erreicht hat.11 matplotlib und seaborn sind leistungsfähig, denken aber grundlegend anders. Wer einmal ggplot2 wirklich beherrscht, will nur ungern zurück.
Dass ggplot2 auch im professionellen Datenjournalismus Maßstäbe setzt, zeigt das Beispiel der New York Times: Das Datenjournalismus-Team der NYT zählte zu den frühen Anwenderinnen und Anwendern von R und nutzte ggplot2, um seinen charakteristischen redaktionellen Visualisierungsstil zu entwickeln.12 Abbildung 5 illustriert die Ausdrucksstärke des Pakets anhand des eingebauten economics-Datensatzes — in einem klaren, redaktionellen Stil:
Noch bedeutsamer für meine tägliche Arbeit ist Quarto, das wissenschaftliche Publishing-System von Posit, das aus R Markdown hervorgegangen ist.13 Quarto ist eine dieser Entwicklungen, die man erst richtig schätzt, wenn man sie intensiv nutzt. Ich verwende es heute für so gut wie alles, was ich schreibe und publiziere: Vorlesungsunterlagen, die als interaktive Webseiten oder PDFs ausgespielt werden können; diese Website; Forschungspapiere, in denen Code, Ergebnisse und Text in einem einzigen Dokument zusammenleben; Präsentationen. All das aus einer einzigen Quelle, in einem einzigen Workflow, mit konsistenter Formatierung und vollständiger Reproduzierbarkeit. Quarto ist inzwischen sprachagnostisch — es unterstützt R, Python, Julia und Observable gleichberechtigt — aber es ist aus der R-Community entstanden, und man merkt es in der Sorgfalt des Designs.
tidyverse, ggplot2, Quarto: Diese Entwicklungen sind nicht nur Werkzeuge, sie sind konzeptionelle Beiträge zur Art, wie wir mit Daten denken und arbeiten — und sie haben weit über die R-Welt hinaus Wirkung entfaltet.
R
tidyverse
ggplot2

Quarto
Python und das Problem der Werkzeugvielfalt
Wer R kennt, sieht das Python-Ökosystem mit anderen Augen. Pythons Stärke — seine schiere Offenheit — ist zugleich seine größte Quelle an operativer Komplexität. Wer heute mit Python arbeitet, steht vor der Wahl zwischen pip, conda, poetry, pipenv und inzwischen uv, jeweils mit unterschiedlichen Verhaltensweisen bei der Versionslösung, unterschiedlichen Lockfile-Formaten und unterschiedlicher Plattformunterstützung.14 In produktiven Umgebungen mit mehreren Projekten und Teams können Versionskonflikte reale Kosten verursachen: Abhängigkeiten, die sich gegenseitig ausschließen; Umgebungen, die auf einem Rechner laufen und auf einem anderen nicht; ich habe Stunden damit verbracht, Fehlermeldungen zu debuggen, die eigentlich nichts mit dem eigentlichen Problem zu tun hatten.
Ein konkretes Beispiel aus 2024 illustriert das gut: Die jeweils neuesten Versionen von proto-plus und grpcio-status ließen sich nicht gleichzeitig installieren, weil beide inkompatible Versionen von protobuf verlangten.15 Neun der hundert meistgenutzten PyPI-Pakete konnten zeitweise nicht gemeinsam auf die neueste Version aktualisiert werden.
Fairerweise muss jedoch gesagt werden: Das Python-Ökosystem arbeitet ernsthaft und erkennbar an diesen Problemen. uv, ein in Rust geschriebener Paketmanager, hat 2025 erheblich an Verbreitung gewonnen und ist nach meiner Einschätzung ein echter Durchbruch für Python.16 Reproduzierbare Lockfiles, saubere Abhängigkeitslisten, eine klare Projektstruktur — und das mit einer Geschwindigkeit, die pip um Größenordnungen übertrifft. Es ist interessant zu beobachten, wie uv konzeptuell in Richtung dessen driftet, was renv in R schon lange geleistet hat — eine gewisse Ironie, die man als R-Nutzender mit einem Schmunzeln zur Kenntnis nehmen darf. Die Grundarchitektur des Python-Ökosystems bleibt jedoch anders als die von R: dezentraler, offener, fragmentierter — mit allen Vor- und Nachteilen, die das mit sich bringt.
Posit: Wenn ein Unternehmen Open Source ernst nimmt
Ein Faktor, der in Diskussionen über R oft unterbewertet wird, ist die Rolle von Posit — 2022 aus RStudio, PBC umbenannt.17 Posit hat ein Geschäftsmodell entwickelt, das sich fundamental von klassischer Software-Kommerzialisierung unterscheidet: Das Unternehmen beschäftigt hauptamtlich die Kernautorinnen und -autoren der wichtigsten R-Pakete — tidyverse, ggplot2, Shiny, Quarto — und finanziert damit deren Weiterentwicklung vollständig als Open Source. Für Nutzerinnen und Nutzer ist alles kostenlos und quelloffen; Posit verdient sein Geld mit Enterprise-Produkten und Hosting. Das Ergebnis ist eine Qualität und Kontinuität in der Paketentwicklung, die rein communitygetriebene Projekte selten dauerhaft aufrechterhalten können.
Auf der IDE-Seite steht heute Positron im Mittelpunkt: eine 2025 allgemein verfügbar gewordene Entwicklungsumgebung, die auf dem quelloffenen Kern von Visual Studio Code (Code OSS) aufbaut — also ein Fork von VS Code, der auf Datenarbeit spezialisiert wurde.18 Das bedeutet: VS-Code-Nutzerinnen und -Nutzer fühlen sich sofort zu Hause — das vertraute Layout, die Tastenkürzel und das gesamte VS-Code-Extension-Ökosystem stehen unmittelbar zur Verfügung. Was Positron darüber hinaus mitbringt, sind auf Datenarbeit zugeschnittene Features, die in VS Code erst mühsam nachgerüstet werden müssten: ein dedizierter Variables Pane, der alle Objekte im Arbeitsspeicher mit Typ, Dimension und Vorschau auflistet; ein integrierter Data Explorer mit Tabellenansicht, Filterung, Sortierung und Spaltenzusammenfassungen; ein Plots Pane, der Visualisierungen direkt neben dem Code anzeigt; sowie native, sprachspezifische Konsolen für R und Python mit vollständiger Code-Vervollständigung. Das alles mit gleichberechtigter Unterstützung für R und Python in einer einzigen Umgebung (vgl. Abbildung 6).
Für die Lehre kommt noch ein weiterer Aspekt hinzu, der in der Diskussion meist völlig übersehen wird: Posit Workbench. Das ist die serverbasierte Variante der Posit-Entwicklungsumgebung, die Posit für Bildungseinrichtungen kostenlos als akademische Lizenz zur Verfügung stellt.19 Ich nutze sie in meinen Lehrveranstaltungen — und der Unterschied ist erheblich. Studierende öffnen einen Browser, melden sich an, und arbeiten sofort in einer vollständig eingerichteten R- und Python-Umgebung. Kein lokales Setup, keine Versionskonflikte auf privaten Laptops, kein “bei mir läuft das nicht” in der ersten Vorlesungsstunde. Alle arbeiten in derselben Umgebung, mit denselben Paketversionen. Für kollaborative Übungen und reproduzierbare Analysen in der Lehre ist das ein Werkzeug, das ich nicht mehr missen möchte.
Keine echte Programmiersprache? Dieser Mythos hält sich hartnäckig
Wer R in gemischten Entwicklerkreisen erwähnt, bekommt mitunter zu hören: R sei keine richtige Programmiersprache. R sei langsam. R tauge nicht für den Produktivbetrieb. Diese Einwände werden seit Jahren wiederholt — und seit Jahren widerlegt. Trotzdem halten sie sich mit bemerkenswerter Beharrlichkeit.
Beginnen wir mit dem direktesten: R ist selbstverständlich eine vollwertige Programmiersprache. Sie ist Turing-vollständig, unterstützt objektorientierte Programmierung in mehreren Ausprägungen (S3, S4, R6), funktionale Programmierung, Metaprogrammierung und First-Class-Funktionen. Der Mythos speist sich vermutlich aus der Beobachtung, dass viele R-Nutzende keine klassischen Softwareentwicklerinnen und -entwickler sind — Statistikerinnen, Biologen, Ökonominnen, die eine Sprache für Datenanalyse gelernt haben, nicht für Systemsoftware. Aber das ist eine Aussage über die Nutzendengemeinschaft, nicht über die Sprache selbst.
Das Argument der Langsamkeit ist differenzierter — und häufig schlicht falsch angewendet. Ja, naive R-Schleifen über einzelne Elemente sind langsam. Das ist aber kein R-spezifisches Problem, sondern das übliche Verhalten interpretierter Skriptsprachen — dasselbe gilt für Python. Der entscheidende Punkt: R wurde von Anfang an um Vektorisierung herum gebaut. Operationen wie mean(), sum() oder lm() sind keine interpretierten R-Schleifen, sondern Aufrufe von hochoptimiertem C-Code im Hintergrund. Wer R so verwendet, wie es konzipiert ist, erhält Laufzeiten, die mit Python auf Augenhöhe liegen. Wer gezielt mehr Geschwindigkeit braucht, greift zu data.table — einem der schnellsten In-Memory-Datenmanipulations-Werkzeuge, die in irgendeiner Sprache verfügbar sind20 — oder zu Rcpp, das die nahtlose Integration von C++-Code in R ermöglicht.21
Was mir als R-Muttersprachler erst beim Erlernen anderer Sprachen bewusst wurde: Vektorisierung ist in R keine Erweiterung — sie ist die Grundannahme. Wenn ich x * 2 schreibe, multipliziert R automatisch jeden Wert des Vektors x, ohne Schleife, ohne explizite Iteration. Das ist so selbstverständlich, dass man es schlicht als normal betrachtet. Der Moment des Erkennens kam erst beim Wechsel zu anderen Sprachen: In Java oder C schreibt man dafür explizite Schleifen, in Python braucht man NumPy. NumPy löst das Problem hervorragend — aber es ist eine Bibliothek, die man hinzuladen muss, nicht das Grundverhalten der Sprache. In R ist Vektordenken keine Konvention, es ist die Sprache selbst.
Und der Produktivbetrieb? Auch hier hat die Wirklichkeit den Mythos längst überholt. Mit plumber lässt sich R-Code mit wenigen Kommentaren in eine vollwertige REST-API verwandeln.22 Shiny ermöglicht die Entwicklung produktionsreifer Webanwendungen direkt aus R heraus — mit eigener Konferenz (Shiny in Production, 2025) und einer wachsenden Enterprise-Nutzerbasis.23 vetiver standardisiert den MLOps-Workflow für das Deployment von Modellen in R und Python gleichermaßen. AWS hat RStudio direkt in Amazon SageMaker integriert — ein klares Signal, dass der Cloud-Anbieter R als produktionsrelevant betrachtet.24 Und auch im Big-Data-Umfeld ist R längst angekommen: Databricks, eine der führenden Datenplattformen, unterstützt R über sparklyr — ein Paket, das eine tidyverse-kompatible Schnittstelle zu Apache Spark bietet und es ermöglicht, R-Code direkt auf Databricks-Clustern und in der Unity Catalog-Umgebung auszuführen.25 In der Pharmaindustrie und klinischen Forschung ist R zudem seit Jahren de facto Standard: Die FDA akzeptiert R-basierte statistische Analysen für regulatorische Einreichungen, und Unternehmen wie Amazon, Google, Ford und Novartis setzen R aktiv in Produktivumgebungen ein.26
Kurz: Die Vorwürfe der Nicht-Vollwertigkeit, Langsamkeit und Produktionsuntauglichkeit beschreiben bestenfalls R aus den frühen 2000er-Jahren — nicht die Sprache und ihr Ökosystem im Jahr 2026.
Wo Python klar gewinnt
Ehrlichkeit gehört dazu: Im Bereich der Künstlichen Intelligenz und insbesondere der generativen KI ist Python schlicht die bessere Wahl. LangChain, Hugging Face transformers, PyTorch, LlamaIndex — diese Bibliotheken haben kein gleichwertiges Pendant in R. Die Dynamik dieser Entwicklung wird von Python getragen, und daran wird sich in absehbarer Zeit nichts ändern. Wer heute große Sprachmodelle feinabstimmt, RAG-Systeme baut oder KI-Agenten entwickelt, arbeitet in Python — nicht aus Gewohnheit, sondern weil die Infrastruktur dort einfach vorhanden ist.
Hinzu kommt ein weiterer Punkt, den R-Nutzende ehrlich benennen sollten: Die Qualitätshürden von CRAN, die ich oben als Stärke beschrieben habe, haben auch eine Kehrseite. Wer ein Paket schnell und iterativ weiterentwickeln möchte, erlebt den CRAN-Prozess als Bremse. Neue Methoden, neue APIs, neue Paradigmen — in PyPI sind sie oft Wochen oder Monate früher verfügbar. Wer am Puls der aktuellen KI-Forschung arbeitet, zahlt für die Verlässlichkeit des Ökosystems mitunter mit Aktualität.
Fazit: Muttersprache mit klarem Verstand
R und Python sind keine Gegner. Sie sind unterschiedlich optimiert — für unterschiedliche Aufgaben, unterschiedliche Kontexte, unterschiedliche Nutzerinnen und Nutzer. Für statistische Modellierung, wissenschaftliche Analysen, reproduzierbare Berichte, Visualisierung und akademisches Publishing bleibt R ein außergewöhnlich gut durchdachtes Werkzeug — gepflegt von einem Core Team mit hohem Qualitätsanspruch, getragen von Posit als institutionellem Rückhalt und bereichert durch eine Gemeinschaft, die ggplot2, das tidyverse und Quarto hervorgebracht hat. Für KI-Entwicklung, große Sprachmodelle und breite Produktionsintegrationen spricht vieles für Python.
In meiner eigenen Arbeit nutze ich beide. Aber wenn ich Daten erkunde, Modelle interpretiere, eine Analyse reproduzierbar machen oder ein Paper schreiben will — dann ist R das Werkzeug der Wahl. Nicht aus Nostalgie, sondern weil es für diese Aufgaben noch immer am besten passt.
Und weil man eine Muttersprache nie ganz verlernt.
Fußnoten
Julie Tibshirani: „If All the World Were a Monorepo” – Substack↩︎
How The New York Times Visualizes Data Using R – Revolution Analytics Blog, 2011↩︎
Quarto – Open-Source Scientific and Technical Publishing System↩︎
Navigating the Python Dependency Hell for Package Publishers – Medium↩︎
Introducing Positron: A New, Yet Familiar IDE for R and Python – Appsilon↩︎
R You Ready? Unlocking Databricks for R Users in 2025 – Databricks Blog↩︎
Options for Deploying R Models in Production – GeeksforGeeks↩︎