Von der bund.dev-Idee über echte API-Hürden bis zur dreischichtigen R-Architektur mit tidy Outputs.
R
OpenData
APIs
DataScience
Autor:in
Michael Bücker
Veröffentlichungsdatum
15. Februar 2026
bund.dev ist eine zentrale Infrastruktur für die Auffindbarkeit und Dokumentation von APIs der Bundesverwaltung.1bunddev überträgt dieses Prinzip in ein R-orientiertes Analysemodell: von der API-Discovery über standardisierte Requests bis zur direkten Weiterverarbeitung in reproduzierbaren Data-Science-Workflows.2
Kurze Geschichte von bund.dev
Die öffentlich verfügbaren Quellen zeigen eine klare Entwicklungslinie:
Im Juli 2021 wurde das Repo bundesAPI/sofortmassnahmen angelegt und als zivilgesellschaftliches Beteiligungsverfahren zum “Zweiten Open Data Gesetz” veröffentlicht.3
Der dort dokumentierte 5-Punkte-Plan setzte das Ziel, bis 2024 Datensätze und Verwaltungsverfahren der Bundesverwaltung per API zugänglich zu machen.4
bund.dev positioniert sich dabei als Entwicklungs- und Dokumentationsportal: APIs auffindbar machen, dokumentieren und für Wiederverwendung öffnen.5
Das Python-Paket bundesAPI/deutschland (seit 2021) zeigt, dass daraus früh ein praktisches Ökosystem entstanden ist und nicht nur eine reine Link-Sammlung.6
Entscheidend: Dieses Fundament wurde von Freiwilligen aufgebaut, obwohl API-Dokumentation institutionell getragen sein sollte. Die Professionalität des Projekts führte teilweise zur Wahrnehmung als offizielles Angebot.78
Damit wurde jedoch auch eine strukturelle Schwäche sichtbar: Eine zivilgesellschaftliche Initiative kompensierte eine staatliche Infrastruktur-Lücke.
Parallel traten Gegenreaktionen auf. Öffentlich wurde beschrieben, dass einzelne Behörden dokumentierte Schnittstellen stärker absichern wollten; dies zeigt sich heute unter anderem im Umfeld der Bundesagentur für Arbeit.9
Der zentrale Punkt bleibt: Open Data ist nur dann wirksam, wenn Daten unter realen technischen Bedingungen tatsächlich nutzbar sind, für Zivilgesellschaft, Wissenschaft und Produktentwicklung.
Warum ein R-Paket?
In R-basierten Data-Science-Projekten entsteht Wert vor allem dann, wenn öffentliche Daten ohne Medienbruch in eine konsistente Pipeline überführt werden:
abrufen
bereinigen
joinen
visualisieren
modellieren
Hier lag die Lücke: Die APIs auf bund.dev sind inhaltlich stark, aber heterogen hinsichtlich Struktur, Authentifizierung und Antwortformaten. Für R-Workflows fehlte eine einheitliche Zugriffsschicht.
Der Aufbau von bunddev: Drei Schichten
Daraus folgt ein dreischichtiger Architekturansatz:10
Fehlerbilder im Betrieb: z. B. Cache-Key-Kollisionen oder HTML-Änderungen, die Scraper/Parser brechen.
Konkret bedeutet das für bunddev: Einige Schnittstellen sind derzeit pausiert, bis belastbare Erreichbarkeit und konsistente Responses wieder gegeben sind:11
Hinzu kommen operative Einschränkungen trotz aktiver Adapter. Beispiel: hochwasserzentralen liefert für lagepegel zeitweise leere Responses. Bei diga ist ein gültiger Bearer-Token erforderlich, wodurch der Zugriff nicht unmittelbar öffentlich reproduzierbar ist.
Praktische Nutzung
Die folgenden Beispiele folgen explizit der Architektur von bunddev: Registry → OpenAPI-Core → Adapter. Damit wird die konzeptionelle Schichtung direkt in einen praktischen Analyse-Workflow übersetzt.
1) Registry-Schicht: APIs entdecken und einordnen
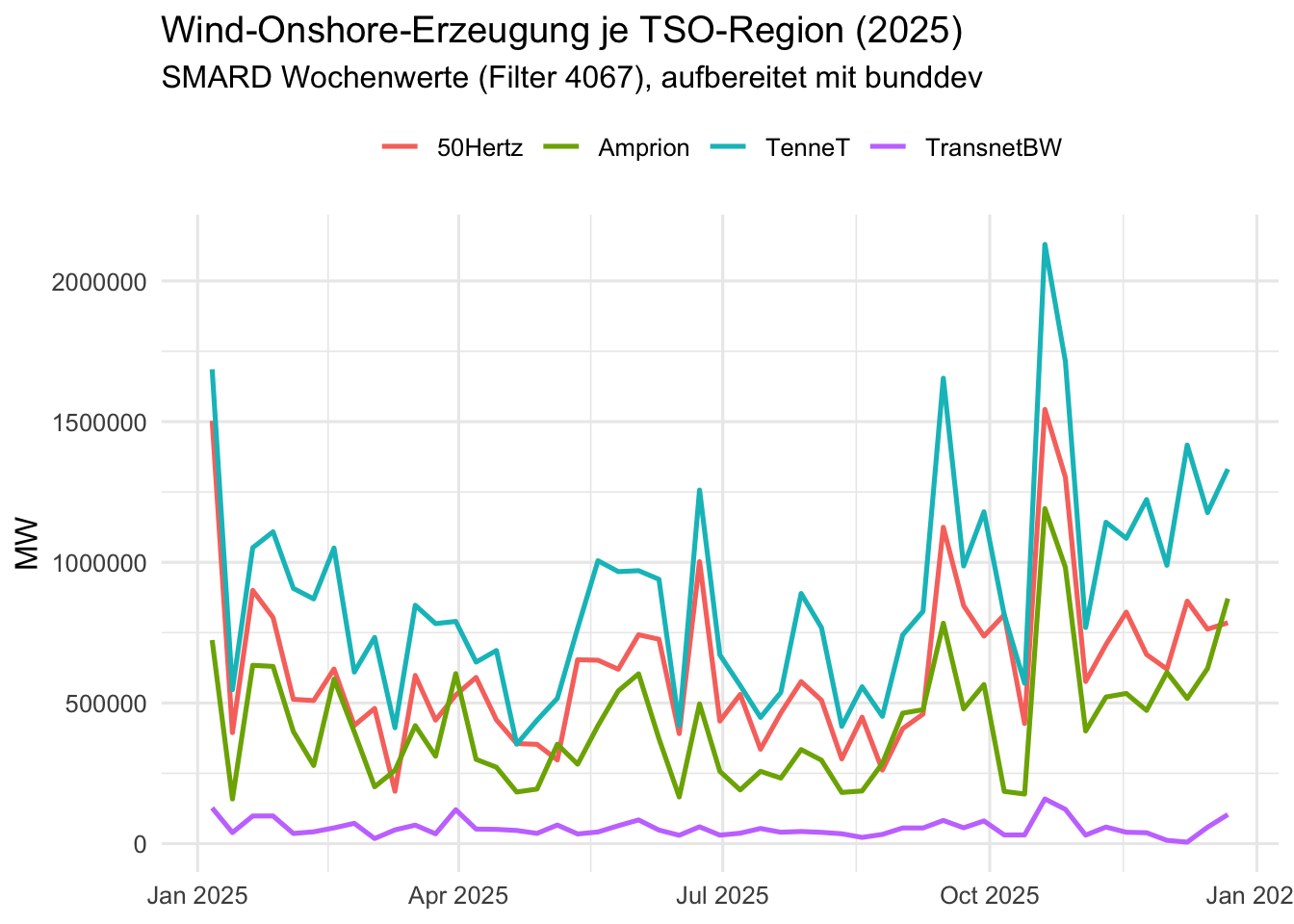
Der erste Schritt ist methodisch bewusst vorgeschaltet: nicht unmittelbar Endpunkte aufrufen, sondern zunächst thematisch passende APIs identifizieren und im Registry-Modell einordnen. bunddev_list(tag = "energy") liefert den Überblick. bunddev_info("smard") ergänzt daraufhin die relevanten Metadaten einer konkreten API, etwa Basis-URL, Tags und Dokumentationslink.
Der Einstieg wird damit reproduzierbar strukturiert: zuerst Discovery, anschließend gezielte Analyse.
library(bunddev)# Welche APIs sind im Bereich Energie vorhanden?bunddev_list(tag ="energy")
# A tibble: 3 × 8
id title provider spec_url docs_url auth rate_limit tags
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <lis>
1 ladestationen Ladesaeulen… Bundesn… https:/… https:/… none <NA> <chr>
2 marktstammdaten Marktdatens… Bundesn… https:/… https:/… none <NA> <chr>
3 smard SMARD API Bundesn… https:/… https:/… none Mehr als … <chr>
# Details zu einer konkreten APIbunddev_info("smard")
# A tibble: 1 × 8
id title provider spec_url docs_url auth rate_limit tags
<chr> <chr> <chr> <chr> <chr> <chr> <chr> <lis>
1 smard SMARD API Bundesnetzagentur https://raw… https:/… none Mehr als … <chr>
2) OpenAPI-Core-Schicht: Spezifikation in robuste Calls übersetzen
Der zweite Schritt adressiert Robustheit: Viele Fehler resultieren aus falsch angenommenen Parametern, etwa IDs, Wertebereichen oder Pfadvariablen. bunddev_parameters("smard") listet die in der Spezifikation definierten Parameter. bunddev_parameter_values(smard_timeseries, "filter") liefert anschließend die zulässigen Filterwerte für exakt die Funktion, die später verwendet wird.
Das reduziert Trial-and-Error und erhöht die Stabilität von Analyse-Notebooks.
# Welche Parameter bietet die SMARD-API laut Spezifikation?bunddev_parameters("smard")
# A tibble: 14 × 8
method path name location required description schema_type enum
<chr> <chr> <chr> <chr> <lgl> <chr> <chr> <lis>
1 get /chart_data/{fi… filt… path TRUE "Mögliche … integer <int>
2 get /chart_data/{fi… regi… path TRUE "Land / Re… string <chr>
3 get /chart_data/{fi… reso… path TRUE "Auflösung… string <chr>
4 get /chart_data/{fi… filt… path TRUE "Mögliche … integer <int>
5 get /chart_data/{fi… filt… path TRUE "Muss dem … integer <int>
6 get /chart_data/{fi… regi… path TRUE "Land / Re… string <chr>
7 get /chart_data/{fi… regi… path TRUE "Muss dem … string <chr>
8 get /chart_data/{fi… reso… path TRUE "Auflösung… string <chr>
9 get /chart_data/{fi… time… path TRUE <NA> integer <chr>
10 get /table_data/{fi… filt… path TRUE "Mögliche … integer <int>
11 get /table_data/{fi… filt… path TRUE "Muss dem … integer <int>
12 get /table_data/{fi… regi… path TRUE "Land / Re… string <chr>
13 get /table_data/{fi… regi… path TRUE "Muss dem … string <chr>
14 get /table_data/{fi… time… path TRUE <NA> integer <chr>
# Mögliche Werte für einen Parameterbunddev_parameter_values(smard_timeseries, "filter")
bunddev ist primär ein Produktivitätswerkzeug für Open-Data-Analysen in R: weniger API-Friktion, mehr Fokus auf die fachliche Fragestellung. Die Kombination aus Registry, generischem OpenAPI-Core und tidy Adaptern macht Datenquellen aus der Bundesverwaltung nicht nur erreichbar, sondern schnell analytisch verwertbar.
Fehlende Adapter oder instabile Endpunkte können jederzeit über Issues und PRs eingebracht werden.